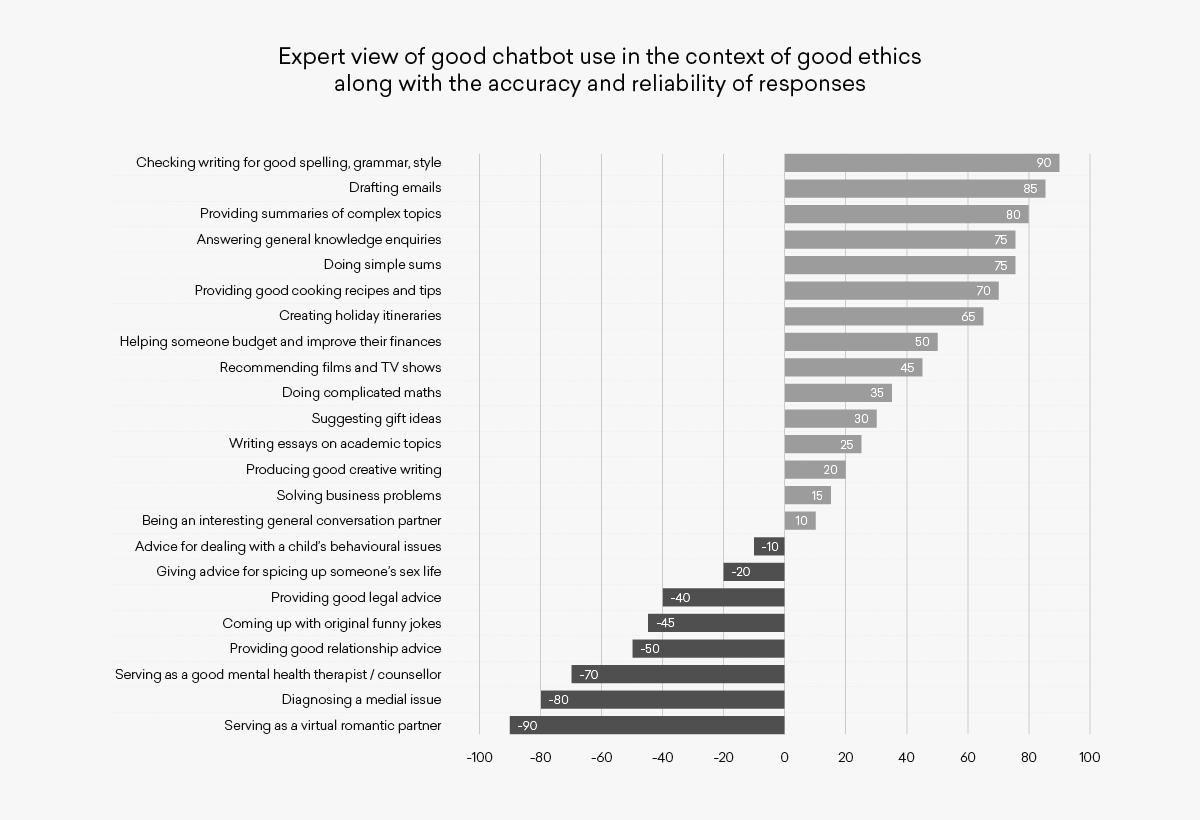
The strongest uses at the top are chatbot staples and deliver high quality and accurate responses. It is worth noting that nothing scores +100 which is a recognition that even for core tasks, the human needs to stay in control and do some checking and assessment of the output. As the numbers decrease below 75 and the “doing simple sums” use case, it’s important to recognise that chatbots can make mistakes if a question is worded poorly or the calculation requested is ambiguous. Getting onto the more complicated maths, the performance against benchmark maths tests suggests good performance, but certainly not getting all the answers right. A score of 35 suggests much more human input to make sure problems are correctly solved, and perhaps stepping through methods and answers with the chatbot.
Suggestions for TV programmes or gifts score positively because, whilst the quality of answers can’t be guaranteed, suggestions which can be taken or ignored are a sound way to use the tool to gain ideas but still exercise human judgement about which ideas are best. This extends to solving business problems and even giving advice on child behavioural issues where suggestions might be useful but it’s important to recognise that the response may not be authoritative or appropriate in the specific circumstances in question. It’s also good to consider here whether you want to use the learned knowledge base of the model, or whether you want to direct the chatbot at a particular authoritative source of your choice. For example, if you wanted to know the answer to a question about GDPR it’s a good idea to direct the chatbot to answer it based on information contained on the Information Commissioner's website rather than leaving it to choose where it gets the information from.
At the bottom of the list in Figure 1 are the use cases which start to become quite problematic. Giving legal advice which is relied on is not recommended, although getting a general idea of the law on a certain subject as part of an information gathering exercise and using it as a guideline can be useful. But the bottom four use cases are fraught with ethical, medical and well being issues and are definitely use cases to take great care with, never favouring the output of chatbots over specific professional or medical advice.
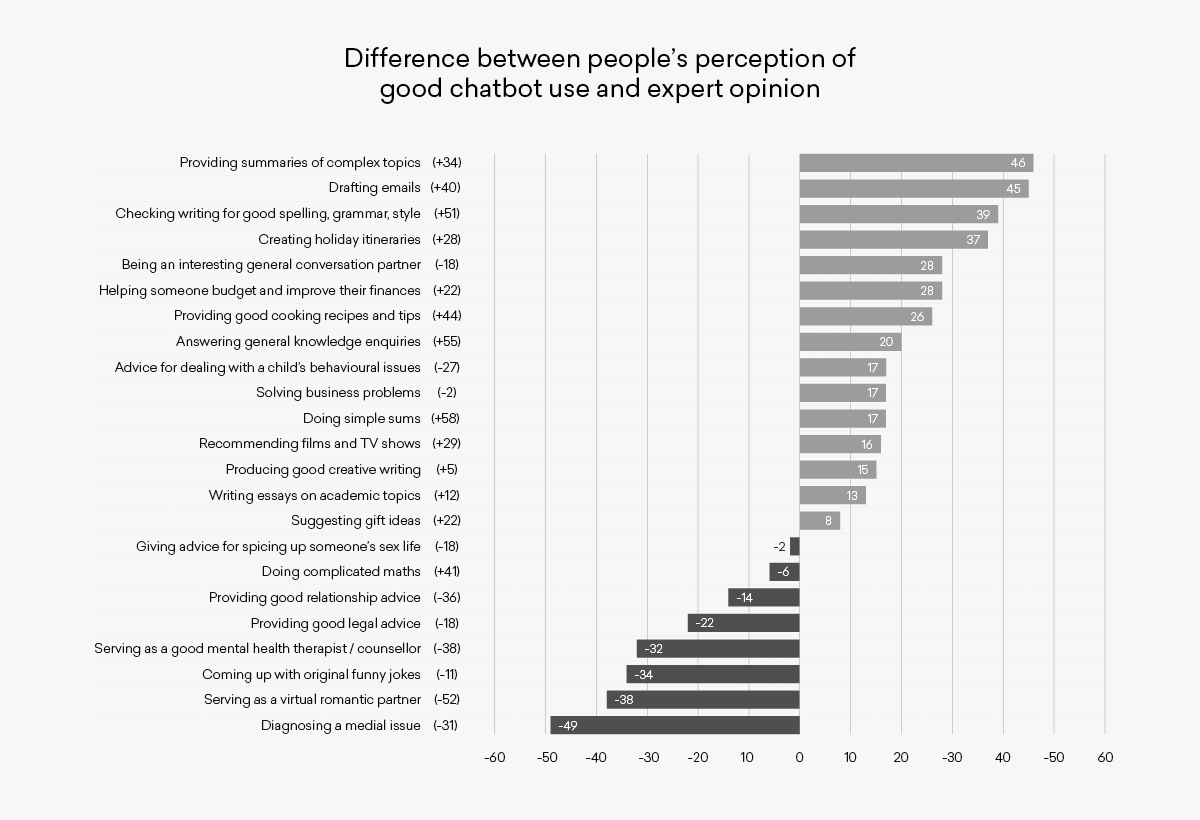
To compare public perceptions against these values, net approval rates were calculated from the Yougov survey for each use case by subtracting the number of people who thought a use case was very or fairly bad from the number of people who thought it was very or fairly good (this is the usual method to arrive at net approval ratings for public figures). A difference was then calculated by subtracting the public net approval score from the expert view to assess how consistent the public view recorded by Yougov is with a more expert view, and where it is most misaligned. A high positive value suggests the public is under-estimating the value of the use case, whereas a large negative value suggests the pubic is over-estimating its value.
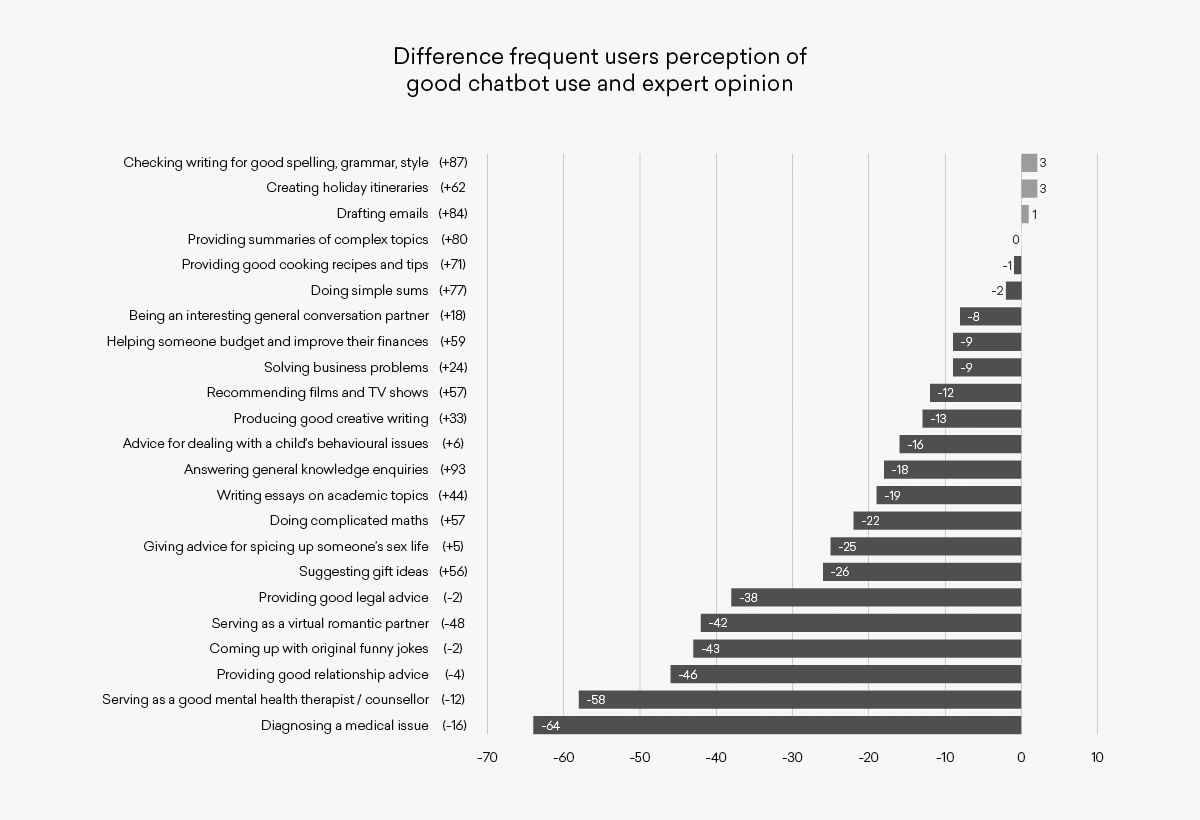
An important point to note up front about the Yougov data is that only 47% of the respondents said they had ever used a chatbot and only 18% used it regularly (i.e. weekly or more often). Clearly therefore many of the answers were submitted as a perception and not based on direct experience. The net approval rating for the full respondent base shows that non-users significantly under-estimate the value of using chatbots for certain purposes.